平常经常用网页看好游快爆的榜单,但网页上内容多加载得太慢,而且一次只能看20个,很多都是以前已经知道的信息,很浪费时间。想批量查询一下游戏名和其他相关信息。
构思和调查网页结构
先看一下预约榜单页面的加载:https://www.3839.com/top/expect.html
进入页面后打开开发者工具-Network,然后刷新网页,找到expect.html文件,打开Response选项卡,就可以看到我们想要的内容。结构比较简单,直接用requests和BeautifulSoup来获取内容即可。
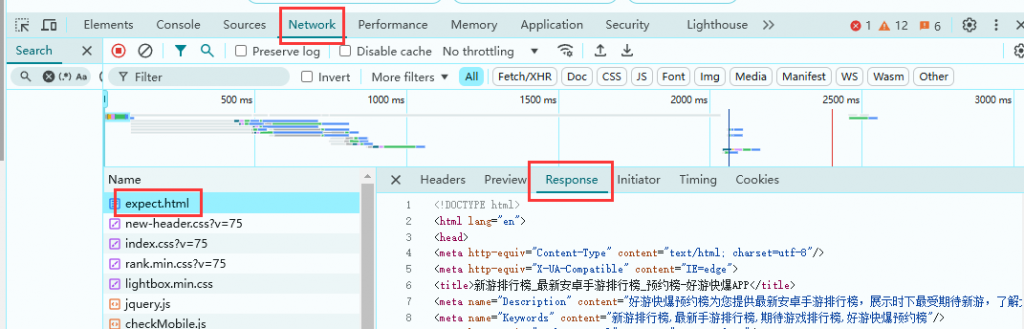
找到我们所需要的内容所在的代码位置,分析规律。去掉无用的信息,然后再用正则表达式把我们想要的内容处理出来(为了下一步)
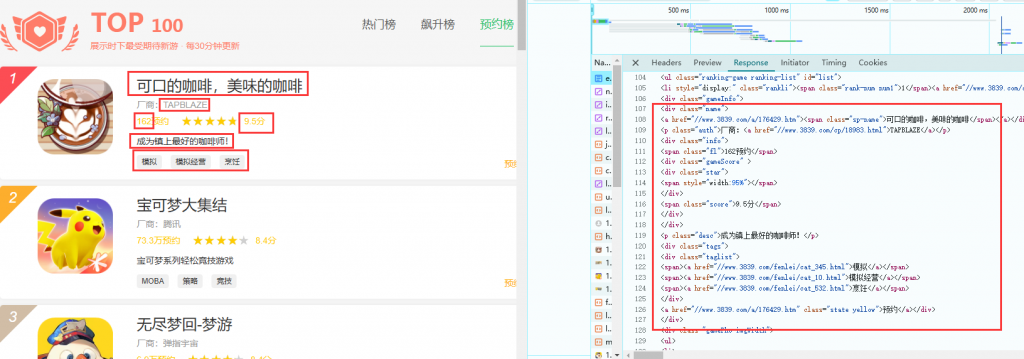
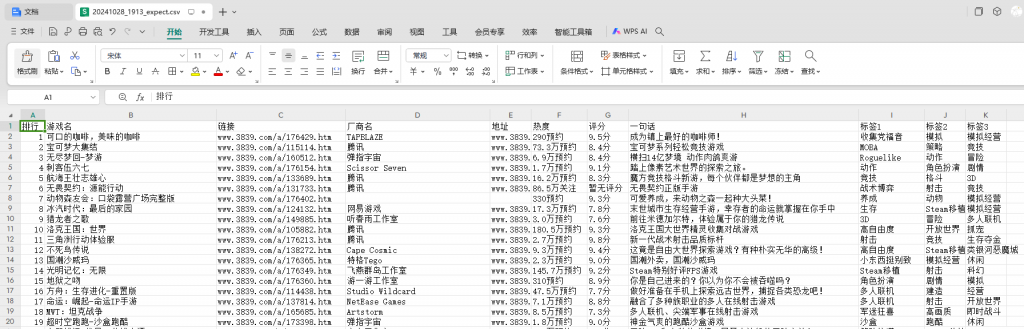
处理之后我希望把它们导出为表格,表格的表头为我们需要的内容:排行,游戏名,链接,厂商名,地址,热度,评分,一句话描述,标签。
实际操作
获取数据
# 目标网页的 URL
url = 'https://www.3839.com/top/expect.html'
#展示时下最受期待新游 · 每30分钟更新
# 发送 HTTP GET 请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 指定编码格式为 UTF-8
response.encoding = 'utf-8'
# 获取网页的 HTML 内容
html_content = response.text
# 使用 BeautifulSoup 解析 HTML 内容
soup = BeautifulSoup(html_content, 'html.parser')将获取到的内容处理后放入date里
# 提取所有纯文本内容和链接内容
all_text = []
for element in soup.recursiveChildGenerator():
if isinstance(element, str):
all_text.append(element.strip())
elif element.name == 'a':
all_text.append(f"{element.text}, {element.get('href')}")
# 去除不需要的部分
start_index = 0
end_index = len(all_text)
for i, text in enumerate(all_text):
if text == '1':
start_index = i
elif text == '加载更多':
end_index = i
break
filtered_text = all_text[start_index:end_index]
# 将提取的内容保存到字符串中
content = "\n".join(filtered_text)
# 定义正则表达式
game_name_link_pattern = re.compile(r'(.+?), //www\.3839\.com/a/(\d+\.htm)')
company_name_link_pattern = re.compile(r'(.+?), //www\.3839\.com/cp/(\d+\.html)')
popularity_pattern = re.compile(r'(\d+(\.\d+)?w?万?关注|\d+(\.\d+)?w?万?预约)')
rating_pattern = re.compile(r'(暂无评分|\d+(\.\d+)?分)')
tag_pattern = re.compile(r'(.+?), //www\.3839\.com/fenlei/')
# 删除符合【预约, //www.3839.com/a/】的行
content = re.sub(r'预约, //www\.3839\.com/a/\d+\.htm', '', content)
# 初始化数据列表
data = []
# 分割小块,确保以纯数字划分
blocks = re.split(r'\n(?=\d+\n)', content)
for block in blocks:
block = block.strip()
if block.endswith(', https://img.'):
block = block[:-len(', https://img.')].strip()
# 初始化字典存储当前块的数据
entry = {
'排行': '',
'游戏名': '',
'链接': '',
'厂商名': '',
'地址': '',
'热度': '',
'评分': '',
'一句话': '',
'标签1': '',
'标签2': '',
'标签3': ''
}
# 提取排行
rank_match = re.match(r'(\d+)', block)
if rank_match:
entry['排行'] = rank_match.group(1).strip()
# 查找游戏名和链接
game_match = game_name_link_pattern.search(block)
if game_match:
entry['游戏名'] = game_match.group(1).strip()
entry['链接'] = 'www.3839.com/a/' + game_match.group(2).strip()
# 查找厂商名和地址
company_match = company_name_link_pattern.search(block)
if company_match:
entry['厂商名'] = company_match.group(1).strip()
entry['地址'] = 'www.3839.com/cp/' + company_match.group(2).strip()
# 查找热度
popularity_line = ''
for line in block.split('\n'):
if popularity_pattern.search(line):
popularity_line = line.strip()
break
entry['热度'] = popularity_line
# 查找评分
rating_match = rating_pattern.search(block)
if rating_match:
entry['评分'] = rating_match.group(1).strip()
# 查找一句话
lines = block.split('\n')
rating_index = -1
tag_index = -1
for i, line in enumerate(lines):
if rating_pattern.search(line):
rating_index = i
elif tag_pattern.search(line):
tag_index = i
break
if rating_index != -1 and tag_index != -1 and rating_index + 1 < tag_index:
entry['一句话'] = ' '.join(lines[rating_index + 1:tag_index]).strip()
# 查找标签
tags = tag_pattern.findall(block)
if len(tags) >= 1:
entry['标签1'] = tags[0].strip()
if len(tags) >= 2:
entry['标签2'] = tags[1].strip()
if len(tags) >= 3:
entry['标签3'] = tags[2].strip()
# 将当前块的数据添加到列表中
data.append(entry)导出为CSV,此处还引入了时间模块,定义文件名为时间,方便追溯
# 创建DataFrame
df = pd.DataFrame(data)
# 获取当前时间精确到分钟
current_time = datetime.now().strftime('%Y%m%d_%H%M')
csv_filename = f"{current_time}_expect.csv"
# 保存为CSV文件
df.to_csv(csv_filename, index=False, encoding='utf-8-sig')
print(f"内容已成功保存到 {csv_filename} 文件中。")
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")最终效果
最后的效果,导出的文件是这样,每次可以获取前100款游戏的信息,符合我们的需求。
其他榜单也是同理,只要修改请求的网址和查找的关键字就行。